
This article sits in the middle of an important exchange between Paul Rohan, Aidan Herbert, and my earlier post on PSD3, instant payments, and upstream fraud prevention.
Paul challenged the casual use of the phrase “new paradigm” in security, arguing correctly that most so called innovations are just faster versions of the same reactive model. His point was that PSD3 and Instant Payments expose the limits of downstream detection, AI, and education, because banks must now prevent fraud and other phishing-led attacks before money moves or absorb the loss.
For people who don’t work in banking or payments, PSD3 is the next evolution of EU payment regulation. It updates and expands PSD2 and fundamentally changes how responsibility for fraud is assigned. Under PSD3, banks and payment providers are expected to prevent fraud, not just respond to it.
💰 If a customer is tricked into authorising a payment through impersonation or deception, the default position shifts toward reimbursement. In practice, this means liability increasingly sits with the institution unless it can demonstrate it took effective and proportionate steps to protect the customer. And as an expert in this field, telling people to “stay vigilant”, or explaining how they can “protect themselves” isn’t going to cut it, unless they provide tools like Link Verifier to make that possible.
Instant Payments change the timing and risk profile of fraud. Another EU mandate has brought payments to settle in 10 seconds, 24×7, across the EU. Once money moves, there’s no practical window to investigate, pause, or reverse the transaction. Controls that rely on post event analysis, delayed detection, or customer reporting arrive too late to matter.
Taken together, PSD3 and Instant Payments remove the safety buffer banks previously relied on. Fraud controls must work before trust is placed and before money moves. Any approach that starts after a customer has interacted with a link, login page, or payment request is structurally misaligned with how payments now operate.
This is why fraud prevention is no longer a downstream problem. It’s an upstream one.
The Exchange That Prompted This Article
Aidan Herbert responded to Paul’s post by framing Zero Trust for web links as a true paradigm shift and by drawing a comparison with W3C DID and Verifiable Credentials architecture. My response builds directly on that point.
It grounds the comparison in 10 years of formal standards work and more than 20 years working at the edge of major shifts in how the web, internet, and telecom networks actually function in practice. That includes the early web, messaging services and applications, Web 2.0, the Semantic Web, the Mobile Web, mobile apps, browser software, conversational chatbots, and VR.
The purpose isn’t to debate terminology or labels. It’s to explain why MetaCert exists at all, why the problem it addresses keeps reappearing under different guises, and why Zero Trust for web links isn’t an incremental improvement to existing security models but a structural response to failures that standards bodies, platforms, and regulators have been circling for decades.
Anyone who compares my work to the W3C is a friend 🙂
Standards Lineage and Why Classification Wasn’t Enough
In Aidan Herbert’s response, he frames proactive assurance and Zero Trust for web links as mapping cleanly to W3C DID and Verifiable Credentials architecture. That point is well made, and there’s a direct lineage worth clarifying.
I’m one of the 7 original founders of the W3C Mobile Web Initiative and a co founder of the W3C standard for URL Classification and Content Labelling that formally replaced PICS in 2009. That work predates DID and VC, but it was driven by the same underlying problem. How people and systems can reliably understand what they’re interacting with on the web.

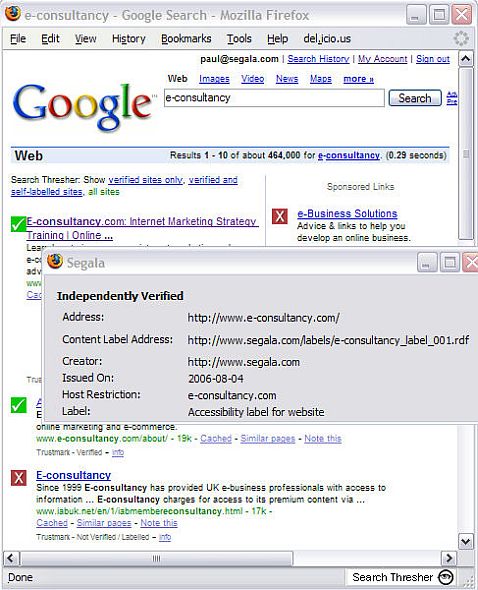
This image shows Search Thresher, a Firefox browser extension I designed in 2006 at Segala, the company I founded before MetaCert. It was later formally endorsed by the W3C as one of the most compelling early implementations of the Semantic Web. MetaCert is a direct technology spin out of that work at Segala.
The goal was simple but ahead of its time. To make trust visible before interaction, not after harm. Search Thresher annotated Google search results in real time using semantic content labels, allowing people to see whether a website had made verifiable claims about its behaviour, standards compliance, and trustworthiness before clicking.
This work directly influenced my later research into classification at scale, visual trust indicators, and human decision making on the web. It also exposed a hard limitation that would later shape MetaCert. No matter how well classification works, it will always lag behind abuse. That insight is what ultimately led me away from detection and toward Zero Trust, where legitimacy must be proven rather than danger inferred.
In other words, this wasn’t a side project. It was an early, practical attempt to solve the same problem we’re still struggling with today. How people and systems decide what to trust online, and why most existing models fail when scaled.
The original intent was self declaration. Website owners would describe their own content and behaviour. In practice, that could never scale. We moved to classification at scale ourselves, which led to a more important conclusion. No matter how fast or sophisticated classification becomes, it’s never fast enough to deal with dangerous or impersonating URLs. That’s the point where we pivoted from threat intelligence to Zero Trust.
Seen through that lens, the parallels Aidan draws make sense.
Where DID and MetaCert Align and Where They Differ
- A W3C DID Document functions as a signed artefact that binds identity, keys, and a service endpoint.
- It allows a relying party to verify and authenticate a service provider at the point of interaction.
- A verifiable data registry underpins that trust, which maps cleanly to MetaCert’s URL registry.
Where MetaCert differs is in how trust is established and scaled. Under the DID model, a business must actively engage an issuer, publish a DID Document, and participate in that ecosystem. MetaCert can passively build verified URL registries through observation, validation, and repeated real world use, without requiring every service to integrate a new identity workflow upfront.
Both approaches have value, particularly as we move toward agentic AI where traditional OAuth tokens don’t scale cleanly across chains of domains and services moving from A to B to C to D.
From my experience, there’s no need for unnecessarily complex machinery to make reliable assertions about web resources. APIs are the right abstraction. That’s why the name MetaCert exists. Certified or verified information expressed as metadata. I believe it was one of the first companies in the world to include “meta” in the name for this purpose.
For additional context, I was also one of the first invited experts to the Semantic Web Education and Outreach programme in the early days, when Web 2.0 was framed as a competing model. My role was to bridge those two worlds, which is effectively the same problem we’re still solving today.
Why This Matters Now
What ties this back to PSD3 and instant payments is simple.
Fraud liability has moved upstream. Detection after the fact no longer protects banks, payment providers, or customers. Any model that assumes trust by default and tries to spot malice later is structurally misaligned with how money now moves.
That’s why the distinction Paul Rohan makes matters, and why Aidan’s framing is correct. Zero Trust for URLs isn’t a faster filter. It’s a reversal of the core assumption. From chasing bad to confirming legitimate.
That shift is what makes prevention possible before a transaction, not after the loss.